Les méthodes pour duper les LLM se multiplient
Malgré la mise en place de garde-fous et d’entraînement à refuser les requêtes dangereuses, les LLM restent vulnérables. Les experts rivalisent d’ingéniosité pour tromper les modèles et les forcer à divulguer des données sensibles.
Phrases longues sans ponctuation, caractères Unicode invisibles, re-taillage d’images, sont autant de techniques pour tromper les LLM. Les experts en sécurité rivalisent d’ingéniosité pour emmener les modèles à publier des données sensibles malgré les services de protection. Ce qui fait dire à David Shipley, CEO de Beauceron Security interrogé par CSO, « la réalité avec beaucoup de grands modèles de langage, c’est que leur sécurité est comme une clôture mal conçue, pleine de trous qu’on tente de réparer sans fin ». Retour sur des techniques récentes pour berner les LLM.
L’efficacité des phrases interminables
Généralement, les LLM sont conçus pour rejeter les requêtes malveillantes grâce à l’utilisation de logits (des prédictions brutes et non normalisées produites par LLM). Lors du travail d’optimisation, des tokens de refus sont présentés aux modèles et les logits sont ajustés pour rejeter les requêtes malveillantes. Ce processus présente toutefois une lacune que les chercheurs de l’Unité 42 de Palo Alto Networks appellent « écart logit refus-affirmation ». En réalité, l’alignement n’élimine pas le risque de réponses malveillantes.
Le secret réside dans une grammaire incorrecte et des phrases interminables. « Une règle empirique pratique émerge », ont écrit les experts. « Le principe est de ne jamais terminer la phrase. Tant qu’aucun point final n’est posé, le modèle de sécurité a moins de chances de reprendre la main », expliquent-ils. Les taux de réussite atteignent 80 à 100 % selon les modèles (Gemma de Google, Llama de Meta, Qwen,…), et 75 % pour le dernier modèle open source d’OpenAI, gpt-oss-20b.
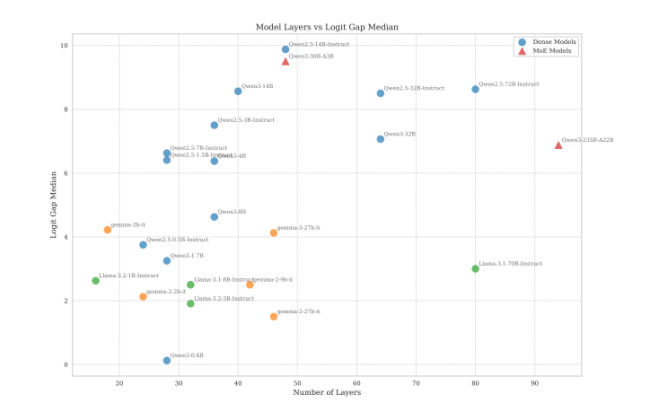
Une technique simple de prompts longs et sans ponctuation trompe les LLM pour obtenir des données sensibles (Crédit photo: Palo Alto Networks)
Re-taillage d’images et données exfiltrées
Des experts de Trail of Bits, spécialisée dans la détection et l’analyse de vulnérabilités, ont montré qu’il est possible de dissimuler des instructions malveillantes dans des images utilisées avec des LLM. À taille normale, l’image paraît banale, mais lorsqu’elle est réduite par le modèle, du texte invisible à l’œil nu apparaît. Dans leurs tests, une image a par exemple réussi à faire exécuter à Google Gemini CLI la commande suivante : vérifier un calendrier professionnel et envoyer par e-mail des informations sur les prochains événements. Le modèle a interprété l’instruction comme légitime et l’a exécutée. Les spécialistes précisent que cette attaque dépend des algorithmes de réduction d’image propres à chaque modèle, mais qu’elle a fonctionné sur plusieurs outils de Google, notamment Gemini CLI, Vertex AI Studio, interfaces web et API, Assistant et Genspark. La dissimulation de code malveillant dans les images n’est pas nouvelle et est « prévisible et évitable », a souligné David Shipley. « Cet exploit illustre surtout que la sécurité de nombreux systèmes d’IA reste conçue a posteriori », a-t-il ajouté.
Par ailleurs, une autre étude menée par la société de cybersécurité Tracebit a montré que des acteurs malveillants pouvaient accéder silencieusement aux données grâce à une « combinaison toxique » associant injection de prompts, validation incorrecte et expérience utilisateur mal conçue, qui ne parvient pas à signaler les commandes risquées. »
Des instructions cachées dans des images deviennent exploitables par les LLM lorsqu’elles sont réduites. (crédit photo: Trail of Bits)
Une sécurité pensée après coup
Pour Valence Howden, conseiller chez Info-Tech Research Group, les failles actuelles de l’IA proviennent d’une compréhension limitée du fonctionnement réel des modèles. La complexité et le caractère évolutif des LLM rendent les contrôles statiques largement inefficaces. « Il est difficile d’appliquer efficacement des mécanismes de sécurité avec l’IA ; sa nature dynamique nécessite des adaptations constantes », explique-t-il. De plus, près de 90 % des modèles sont entraînés en anglais, ce qui réduit la capacité à détecter des menaces dans d’autres langues. « La sécurité n’est pas conçue pour surveiller le langage naturel comme vecteur de menace », résume Valence Howden.
Même constat pour David Shipley. Selon lui, le problème fondamental est que la sécurité est souvent pensée après coup. La majorité des IA accessibles au public présentent désormais le « pire des mondes en matière de sécurité » et ont été conçues de manière « insécurisable » avec des contrôles maladroits. Il critique également la course à l’augmentation des corpus d’entraînement au détriment de leur qualité. « Les LLM contiennent de nombreuses données toxiques issues de ces grands corpus. On peut les utiliser comme s’ils étaient fiables, mais ces problèmes restent enfouis, et nettoyer l’ensemble de données est pratiquement impossible », explique-t-il. Il conclut par un avertissement : « Ces incidents de sécurité sont autant de coups tirés au hasard. Certains atteindront leur cible et causeront de véritables dommages. »